What Percent Of The Residuals Are Greater Than 8cm
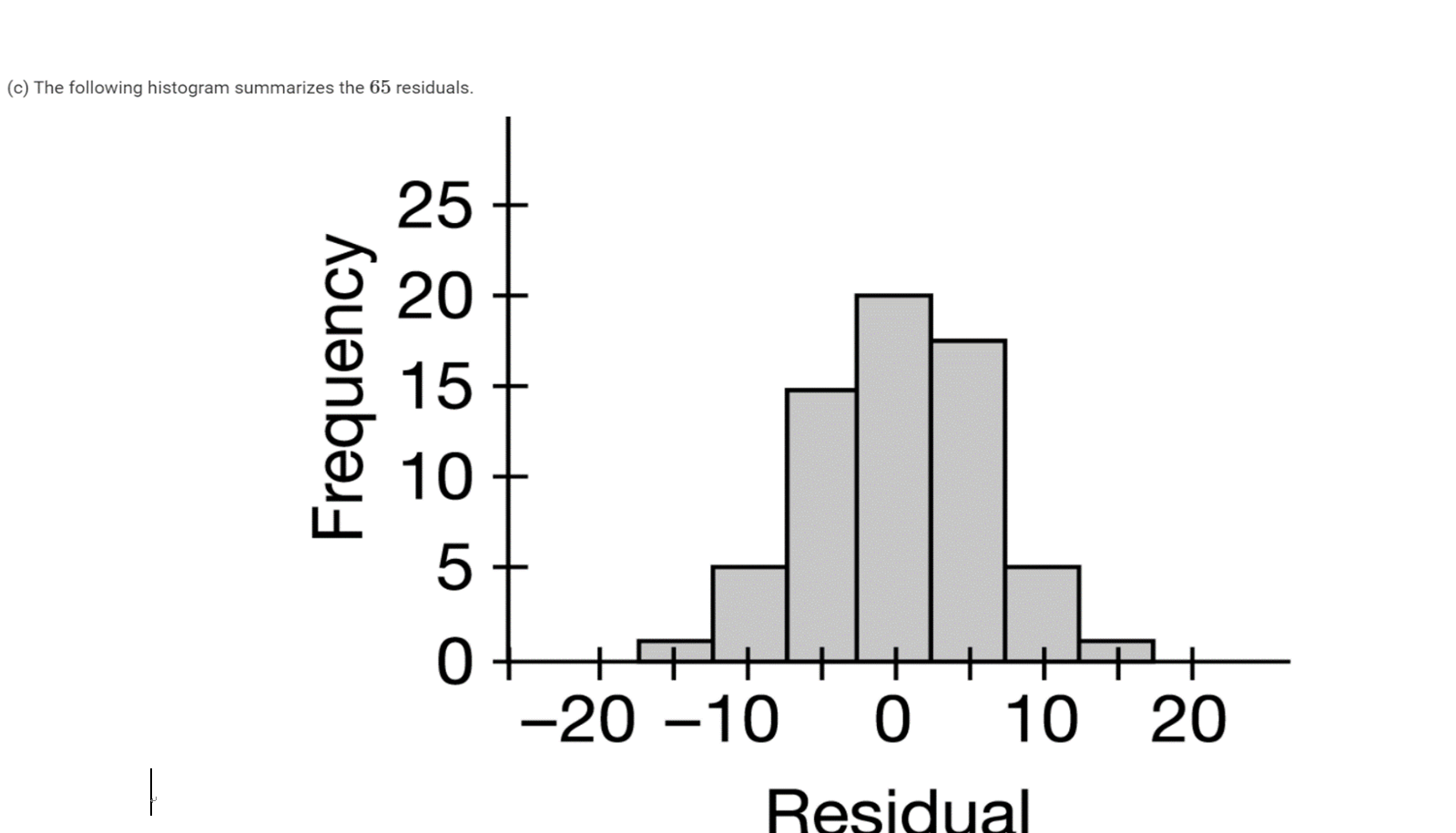
Hey there, awesome data explorer! So, you've been diving into some numbers, huh? Maybe you're working on a project, trying to understand some cool information, or maybe you just like making your computer do math. Whatever the reason, you've probably stumbled upon this phrase: "What percent of the residuals are greater than 8cm?"
Now, before your eyes glaze over like a donut at a bake sale, let's break this down. It sounds super technical, like something a rocket scientist would say while wearing a lab coat covered in coffee stains. But trust me, it's actually pretty straightforward and, dare I say, even a little bit fun!
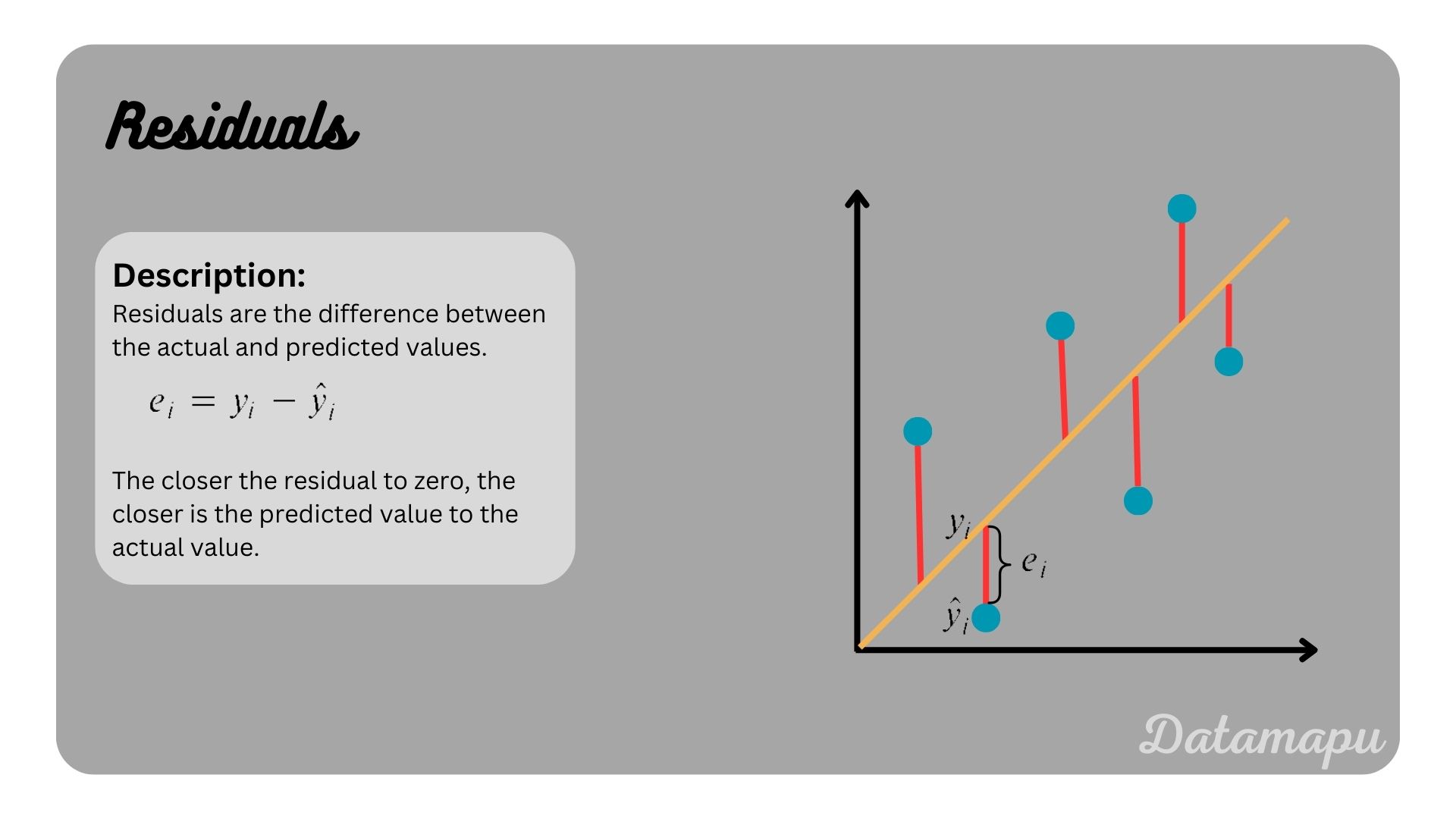
Think of it this way: Imagine you're trying to predict something. Let's say you're trying to guess the height of a friend based on how many cups of coffee they drink in a day. You make a prediction, and then you measure their actual height. The difference between your prediction and their actual height? Voila! That's a residual. It's the little oopsie, the error, the "almost but not quite" part of your prediction.
So, when we talk about "residuals," we're basically talking about how far off our predictions were from the real deal. Some predictions will be spot on (hooray for accuracy!), some will be a little bit off, and some might be way, way off. It's all part of the learning process, right? Nobody's perfect, not even our prediction models!
Now, the "8cm" part. This is just a threshold, a line in the sand. We're not interested in all the residuals; we're specifically looking at the ones that are a bit… bigger. Think of it like this: You're trying to catch butterflies with a net. Some butterflies will be small and easy to snag. Others are like little speed demons, zipping around. The 8cm is like saying, "Okay, I'm only really worried about the butterflies that are this big or bigger. The little ones? Meh, they're fine."
So, "What percent of the residuals are greater than 8cm?" is asking: Out of all the times our prediction was a bit off, how many of those "offs" were pretty significant? How many times was our prediction more than 8cm away from the actual value? We're trying to get a feel for the magnitude of our errors. Are our errors mostly small and insignificant, or do we have some big, honking errors that we need to pay attention to?
Let's dive a little deeper into why we'd even care about this. In the wonderful world of statistics and data analysis, we're often trying to build models. These models help us understand relationships, make predictions, and generally make sense of the chaos that is data. A good model is like a well-trained dog – it listens to you, it's reliable, and it doesn't chew up your favorite shoes (or, you know, produce wildly inaccurate predictions).
When we build a model, we usually have a goal. Maybe our goal is to predict house prices, or the temperature tomorrow, or how many likes your cat photo will get (that last one's a tricky one, I'll tell you!). We use data from the past to teach our model. Then, we test it on new data to see how well it does.
The residuals are our report card. If all our residuals are tiny, like the size of a gnat's elbow, then our model is doing a fantastic job. It's like it's got X-ray vision for your data! But if we have a lot of big residuals, especially ones bigger than our 8cm threshold, it means our model might be struggling. It's like it's wearing glasses with the wrong prescription – things are a bit blurry.
So, when someone asks, "What percent of the residuals are greater than 8cm?", they're essentially asking about the reliability and accuracy of your model. Are there a lot of times when your model is making a pretty big mistake? A low percentage here is generally a good thing! It means your model is consistently close to the real answer. A high percentage? Well, that means you might have some work to do to make your model smarter. Perhaps it's missing some crucial information, or maybe the relationship between the things you're trying to predict isn't as straightforward as you thought.
Imagine you're a chef trying to predict how much pasta to cook for a dinner party. You have a recipe that usually serves 8. But sometimes, your guests are extra hungry, and you end up short. The difference between how much you cooked and how much they ate? That's a residual. If the residual is always small, like you only cooked 50g extra, that's great! But if sometimes the residual is a whole kilogram of pasta (that's a lot of spaghetti!), then your prediction method for pasta needs some serious tuning. The 8cm in our example is like that "kilogram of pasta" – a significant deviation.
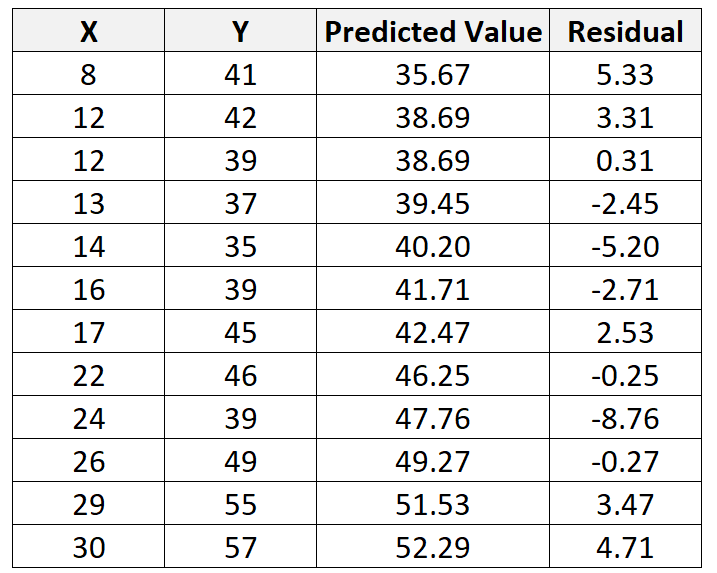
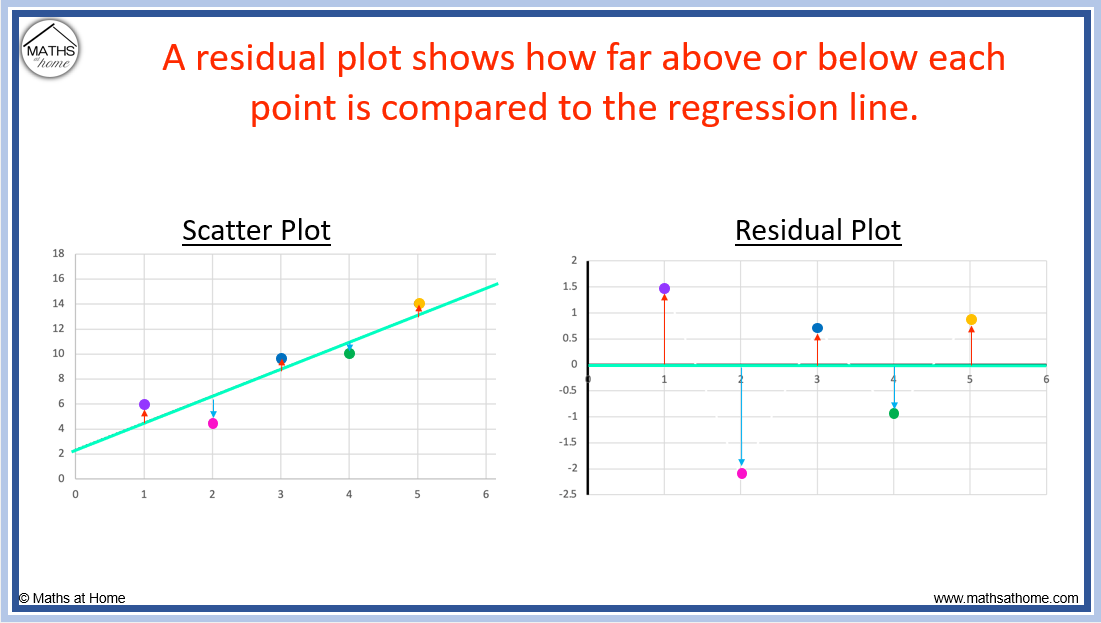
Let's get a bit more specific, shall we? In statistical modeling, we often use something called regression analysis. This is where we try to find a line (or a curve, for the more adventurous!) that best fits our data points. Think of it like drawing the best possible line through a scatter plot of dots. The residuals are the vertical distances between each dot and that line. Our model draws the line, and the residuals tell us how far each point is from that line.
So, if you have a scatter plot of, say, student study hours versus their exam scores, and you draw a regression line, the residuals are the differences between the actual exam scores and the scores predicted by your line. If you're asking "What percent of the residuals are greater than 8cm?", you're saying, "Of all the students, how many had an exam score that was more than 8 points away from what my model predicted?" A low percentage here means your model is pretty good at predicting exam scores based on study hours. A high percentage suggests other factors might be at play, or your model needs some tweaks.
Why is this useful? Well, in business, it could be about predicting sales. If your sales prediction model often has residuals greater than, say, $10,000, that's a significant issue! It means your forecasts are often off by a substantial amount, which can lead to poor inventory management, wasted marketing dollars, or missed opportunities. You'd want that percentage to be as low as possible.
In the medical field, it could be about predicting patient recovery time. If your model predicts a certain recovery time, and the actual recovery time is often significantly longer (greater than your 8cm, or in this case, your 8-day threshold), it could have serious implications for patient care and resource allocation. You'd want that percentage of large discrepancies to be tiny.
Even in something as simple as gardening, you might try to predict how tall a plant will grow based on the amount of sunlight it gets. If your predictions are often off by more than 8cm, your plant might not be getting what it needs, or maybe the soil quality is a bigger factor than you initially thought. Gasp! The plant's feelings are hurt!
So, how do you actually find this percentage? Well, it's not magic, but it does involve a little bit of number crunching. Typically, you'll have a dataset, and you'll have run your model to get predicted values. You'll then calculate the residual for each data point by subtracting the predicted value from the actual value. Then, you take the absolute value of these residuals (because we care about the size of the error, not whether it was too high or too low – a 10cm error is a 10cm error, whether it's +10 or -10).
After that, you'll count how many of those absolute residuals are greater than your 8cm threshold. Let's say you have 100 data points in total. If you find that 15 of those residuals are greater than 8cm, then congratulations! You've done it! The percentage is 15%.
It’s like sorting through a big pile of LEGO bricks. You're looking for the ones that are bigger than a certain size. You pick up each brick, measure it (mentally, or with a ruler if you're feeling fancy!), and if it's bigger than your "8cm" brick, you put it in a special pile. At the end, you count how many bricks are in your special pile compared to the total number of bricks you started with. Easy peasy, lemon squeezy!

Now, why 8cm? In a real-world scenario, that number would come from the context of your problem. Maybe 8cm is considered a "practically important" difference. For example, if you're measuring the length of a car part, a difference of 1mm might be critical for fitting. If you're measuring the distance between cities, 8cm is… well, it's not much of anything! So, the choice of that threshold is highly dependent on what you're measuring and why.
But for our general understanding, think of it as a way to focus on the significant errors. Small errors are expected, but large errors are red flags. They tell us something isn't quite right, and we need to investigate further.
So, when you see that question, "What percent of the residuals are greater than 8cm?", don't panic. It's simply a way of asking: "How often is my prediction off by a notable amount?" It's a measure of how much your model might be missing the mark on the bigger picture. A low percentage is a sign of a strong, reliable model. A high percentage is an invitation to dig deeper, learn more, and make your model even better!
And that, my friend, is the beauty of it. Every piece of data, every residual, is a story. It's a chance to learn, to refine, and to get closer to understanding the world around us. So, the next time you encounter this question, don't just see numbers. See an opportunity to make your models shine, to uncover hidden truths, and to become a data detective extraordinaire! Keep exploring, keep questioning, and keep that smile on your face as you unlock the secrets within your data. You've got this!