The Relative Frequency Of A Class Is Computed By _____.

You know, I was staring at a pile of socks the other day. Don't ask why, my life isn't always filled with existential sock-sorting crises. Anyway, I had so many black socks. Like, an absurd amount. Then there were a couple of pairs of navy blue, a few strays of grey, and then… a single, lonely, bright red sock. It looked so out of place, so… unique.
And it got me thinking. If I were to, hypothetically, try and quantify the sock situation in my laundry basket (a task I highly do not recommend for your own sanity), I'd probably want to know how common each color was. That red sock? It’s a rare bird. The black ones? Practically the dominant species.
This whole sock-sorting epiphany, as dramatic as it sounds, actually leads us to a pretty cool concept in statistics. It’s all about understanding how often something shows up compared to everything else. And when we’re talking about data, and particularly when we’re trying to make sense of groups of data – what we call classes – there’s a specific way to measure this “show-up-ness.”
The Humble, Yet Mighty, Relative Frequency
So, how do we figure out if our black socks are truly outnumbering the grey ones in a statistically significant way? Or, in more formal (but still friendly!) terms, how do we compute the relative frequency of a class?
The answer, my friends, is surprisingly straightforward. You compute it by dividing the frequency of the class by the total number of observations.
Boom. Mic drop. (Okay, not really, this is a blog post. But you get the idea.)
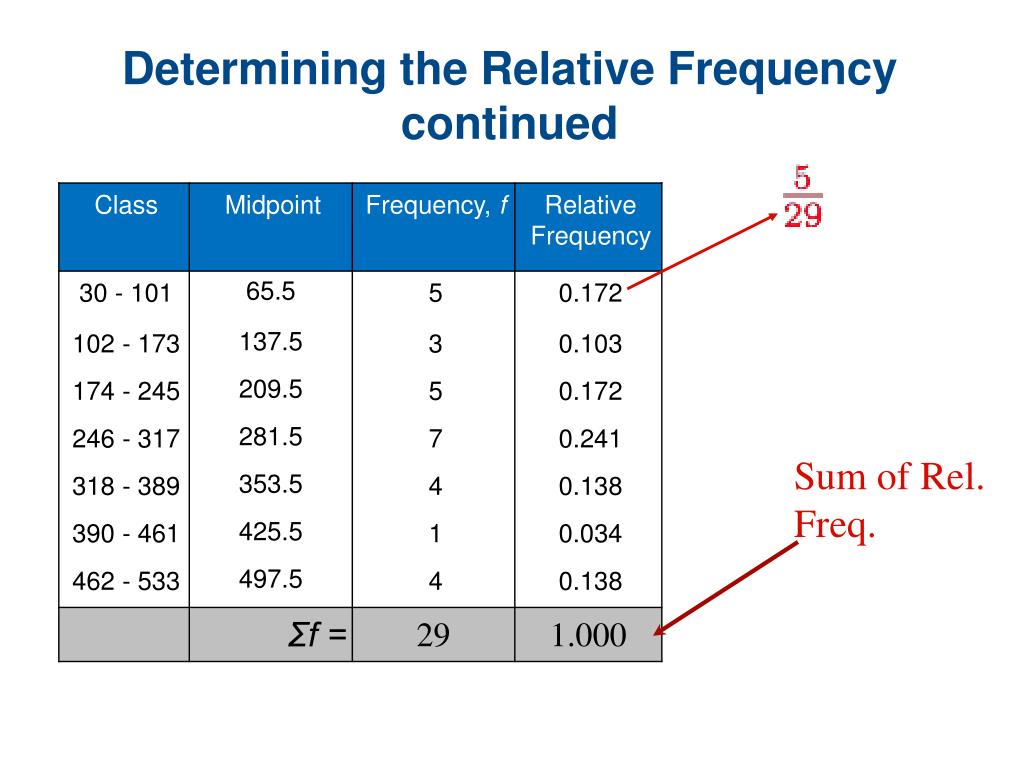
Let's break that down, because while the formula is simple, understanding why it works and what it tells us is where the real magic happens. Think of it like this: you’ve got your sock drawer, or your spreadsheet, or your survey results. These are your observations. Each category, like “black socks,” “blue socks,” “red socks,” or “people who prefer coffee,” is a class.
Frequency: The Raw Count
First, we need the frequency of the class. This is just the simple, unadulterated, plain-vanilla count of how many times a particular class appears in your data. For my sock example, the frequency of the “black sock” class would be the total number of black socks I possess. Let’s say, just for fun, it's 20 pairs. The frequency of the “red sock” class? A measly 1. (Poor little guy.)

In a more serious context, if you were surveying people about their favorite ice cream flavors and 50 people said “chocolate,” then the frequency of the “chocolate” class is 50. Simple, right? No fancy math yet. Just counting.
Now, this raw frequency is useful, no doubt. It tells you “there are 50 people who like chocolate.” But it doesn’t tell you how popular chocolate is compared to, say, vanilla, or strawberry, or that one weird flavor your aunt likes that involves anchovies (please, tell me that’s not a thing!).
Total Observations: The Big Picture
Next up, we need the total number of observations. This is the grand total of everything you’ve counted. In my sock saga, it would be the sum of all the socks (or pairs of socks, we’re being loose with definitions here). So, if I have 20 pairs of black, 2 pairs of blue, 3 pairs of grey, and 1 lonely red sock, my total number of “sock units” is 20 + 2 + 3 + 1 = 26. (Again, don’t overthink the sock logic, it’s a rabbit hole.)
In our ice cream survey example, if you surveyed 200 people, then the total number of observations is 200. This number is crucial because it provides the context for our frequencies. 50 chocolate lovers sounds like a lot, but what if everyone loves chocolate? Then it’s not as special.
The Grand Finale: Division!
And now, the moment of truth! We take the frequency of the class (the count for one specific category) and we divide it by the total number of observations (the grand total count). This gives us the relative frequency.
So, for my sock collection:
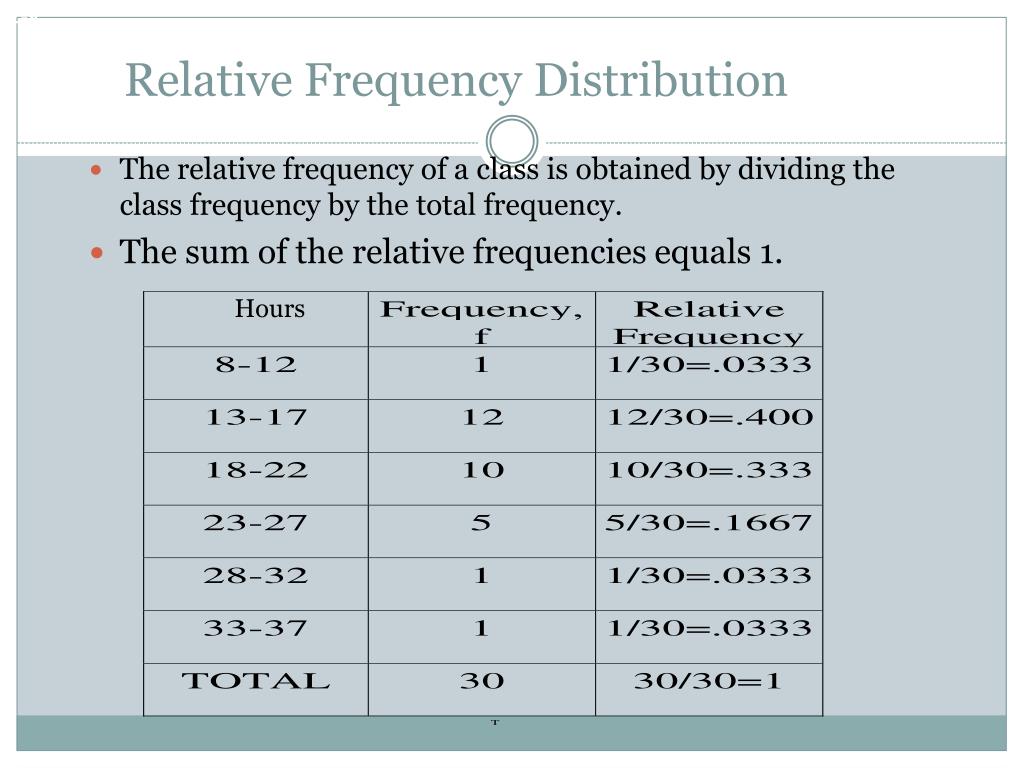
- Relative frequency of black socks = 20 / 26 ≈ 0.77
- Relative frequency of blue socks = 2 / 26 ≈ 0.08
- Relative frequency of grey socks = 3 / 26 ≈ 0.11
- Relative frequency of red socks = 1 / 26 ≈ 0.04
See? The red sock, with its frequency of 1, has a relative frequency of about 0.04. That’s 4%. It’s a small slice of the sock pie. The black socks, with a frequency of 20, have a relative frequency of about 0.77, or 77%. They dominate the sock-verse.
For the ice cream survey, if 50 out of 200 people prefer chocolate:
- Relative frequency of chocolate = 50 / 200 = 0.25
This means that 25% of the people surveyed prefer chocolate. This is much more informative than just knowing “50 people like chocolate.” It puts that number into perspective relative to the entire group surveyed.
Why Bother? The Power of Perspective
So, why is this “dividing thing” so important? Why do we even care about relative frequency? Well, my statistically curious friend, it’s all about comparability and proportion.
Imagine you have two different classes, or two different studies. One might have 100 participants, and the other might have 1000. If you just look at raw frequencies, a class that appears 10 times in the first study (10%) might seem less significant than a class that appears 20 times in the second study (2%). But the second class, even though it has a higher raw count, is actually less frequent proportionally (2% vs 10%).
Relative frequency allows us to make apples-to-apples comparisons. It tells us the proportion or the percentage of times an event occurs, regardless of the total size of the dataset. It’s like comparing the fraction of a pizza you ate to the fraction your friend ate, rather than just saying “I ate 3 slices” and “They ate 5 slices.” Who ate more? Depends on the size of the pizzas, right? Relative frequency removes that ambiguity.
It’s All About Probability, Baby!
And here’s where it gets really interesting. Relative frequency is a fantastic estimator of probability. When you have a large enough sample of data, the relative frequency of an event happening in that sample is a good bet for how likely that event is to happen in the future, or in the population from which the sample was drawn.
Think about it. If your sock drawer has 77% black socks, and you reach in without looking, you have a 77% chance of pulling out a black sock. (Assuming you’re pulling out one sock, and not trying to form a complete pair, which is a whole other statistical nightmare.)
In scientific research, in market analysis, in pretty much any field that deals with data, understanding the relative frequency of different outcomes is key to making informed decisions. It helps us predict, it helps us understand trends, and it helps us avoid, for instance, wearing mismatched socks (unless that’s your jam, no judgment here).
The Practical Side: Where Do We See This?
You encounter relative frequency everywhere, even if you don’t realize it. Ever checked the weather forecast and it said there’s a “30% chance of rain”? That’s a relative frequency! It’s based on historical data about how often it has rained on similar days in that location.
When a company analyzes customer demographics, they’re looking at relative frequencies: what percentage of customers are in a certain age group? What percentage live in a specific region? This helps them target their marketing efforts effectively.
In education, teachers might look at the relative frequency of students scoring above a certain threshold on a test. This tells them about the overall performance of the class and where they might need to adjust their teaching strategies.
Even in sports! A basketball player’s shooting percentage is a relative frequency: the number of shots made divided by the number of shots attempted. It’s a clear indicator of their skill and consistency.
So, next time you’re looking at a statistic that seems to be a percentage or a proportion, you’re probably looking at a relative frequency. It’s the silent workhorse of data analysis, making sense of the chaos and giving us clear, comparable insights.
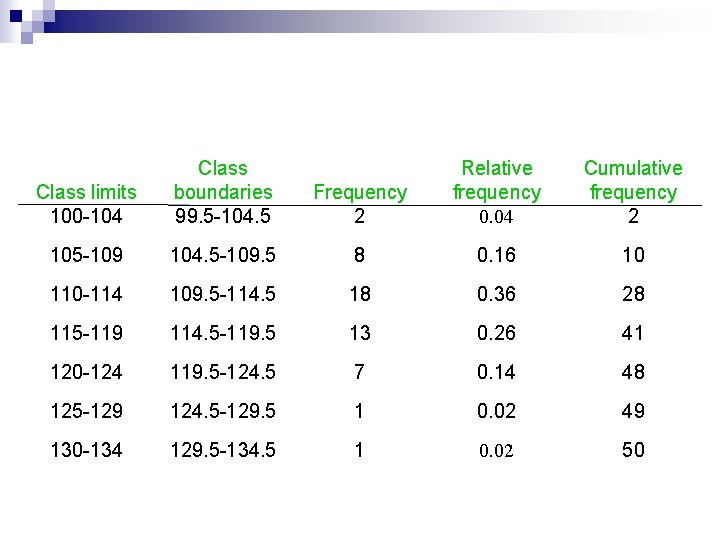
A Quick Word on Cumulative Relative Frequency
And just when you thought we were done, there’s a cool cousin to relative frequency: cumulative relative frequency. This one is about adding up the relative frequencies as you go down your classes. So, if 25% of people prefer chocolate, 20% prefer vanilla, and 15% prefer strawberry, the cumulative relative frequency for strawberry would be 25% + 20% + 15% = 60%. This tells you that 60% of people prefer chocolate, vanilla, or strawberry.
It’s super handy for understanding where a particular class falls within the entire distribution of your data. It answers questions like “What percentage of students scored at or below this grade?”
In Conclusion (For Now!)
So, to circle back to our original, sock-filled question: The relative frequency of a class is computed by dividing the frequency of the class by the total number of observations.
It’s a fundamental concept, but its implications are vast. It transforms raw counts into meaningful proportions, making our data understandable, comparable, and predictive. It’s the bridge between simply observing things and truly understanding their significance in the grand scheme of things. Whether you’re dealing with socks, ice cream flavors, or complex scientific data, relative frequency is your go-to tool for gaining perspective. Now go forth and compute some relative frequencies! Or, you know, just sort your socks. Whichever feels more statistically significant to you.