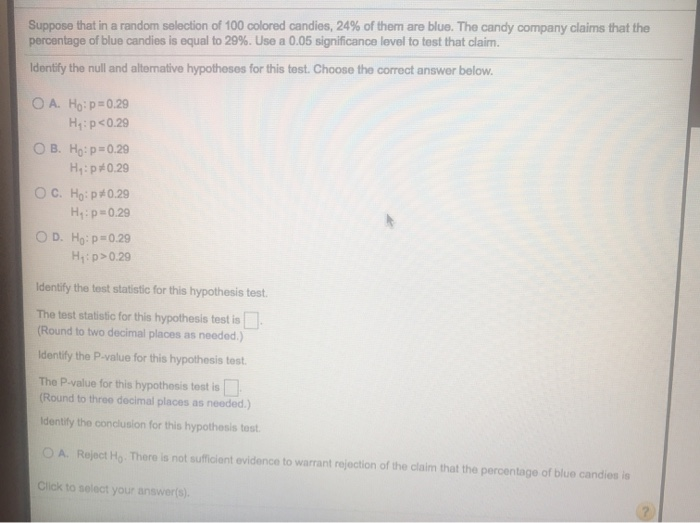
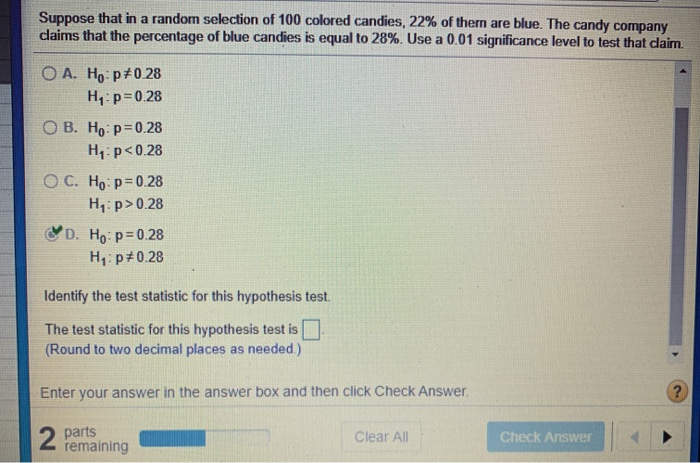
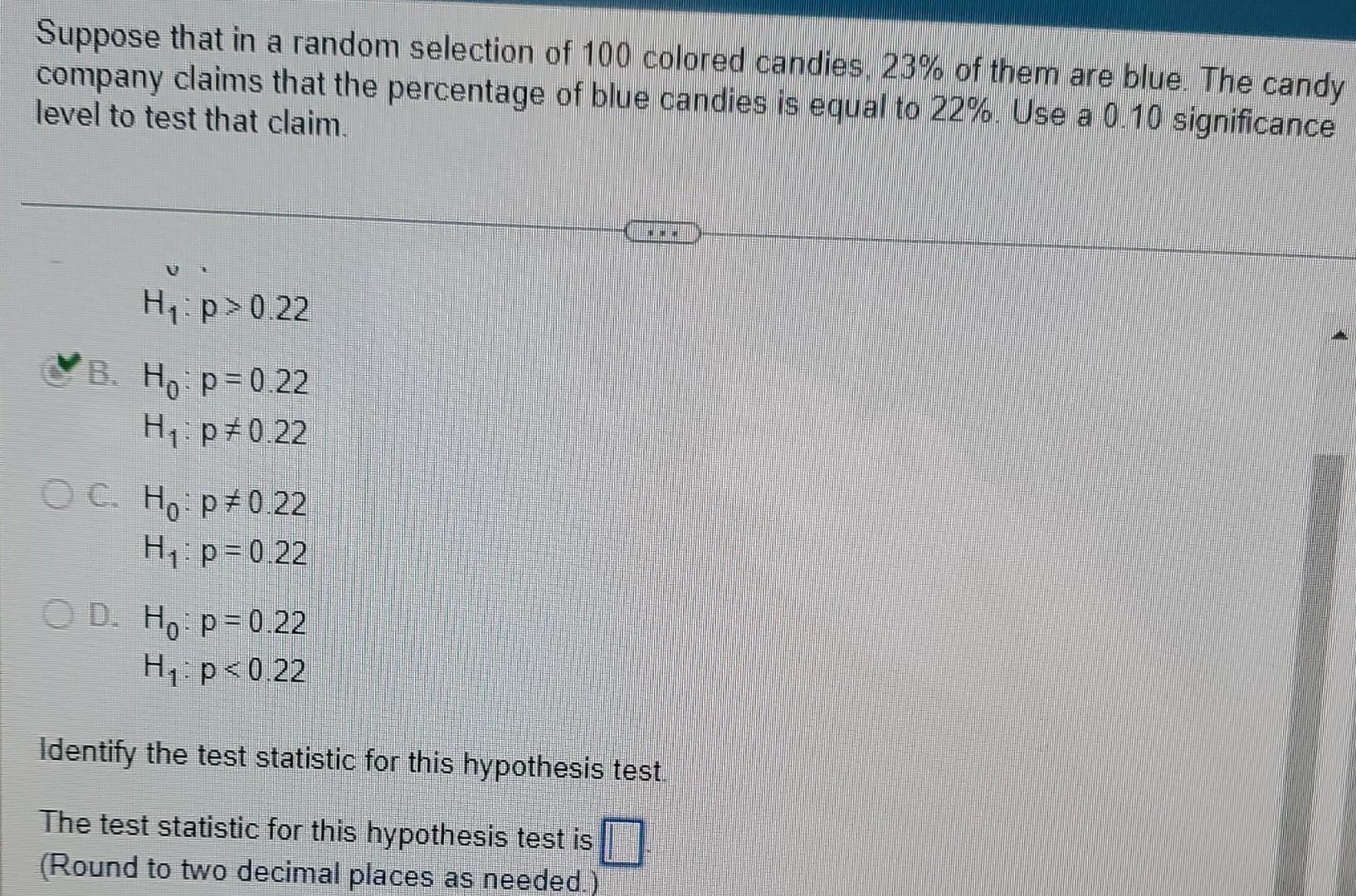
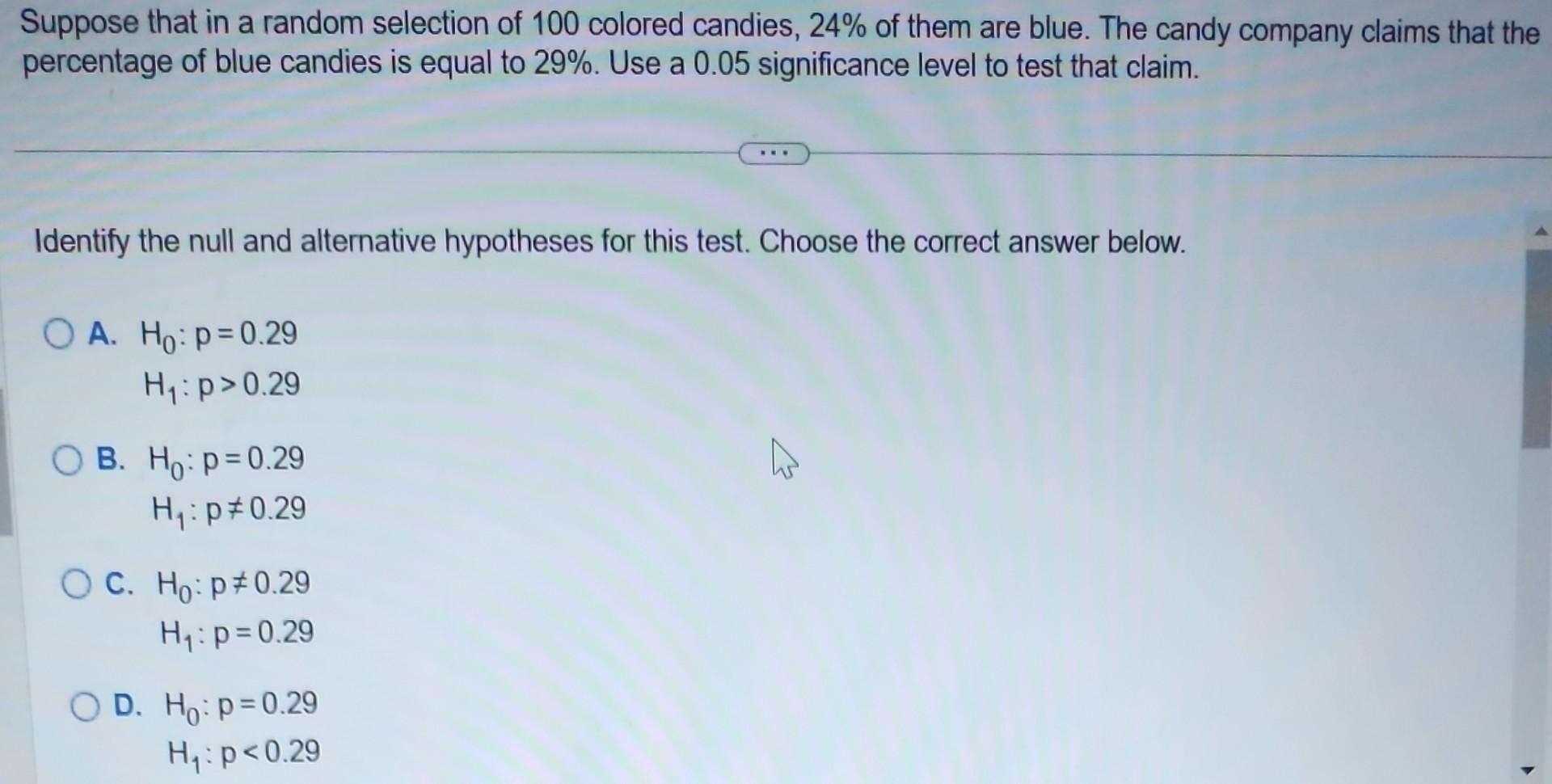
Suppose That In A Random Selection Of 100 Colored Candies

I was digging through a bag of those brightly colored, sugar-coated candies the other day. You know the ones. The kind that promise a burst of artificial fruitiness with every bite. My mission? Purely scientific, of course. I was trying to figure out if there was a reason why I always seemed to snag the green ones first. Call it a personal confectionery conspiracy theory. Anyway, I ended up with about a handful, and as I was popping them into my mouth, a little thought tickled my brain: what if we did this with a lot of candies? Like, a hundred?
So, picture this: a gigantic bag, brimming with a hundred of these little sugary gems. And we, being the intrepid explorers of randomness that we are, decide to pull out exactly 100 of them. Just pluck them out, one by one. No peeking, no strategic fishing for your favorite hue. Pure, unadulterated chance. This, my friends, is where things get surprisingly interesting. It’s like a mini-experiment happening right there in your palm, or on your kitchen counter.
Now, before you start picturing me with a lab coat and a clipboard, let me assure you, my "scientific" endeavors are usually fueled by curiosity and a slightly excessive sweet tooth. But this idea, of randomly selecting 100 candies from a larger, unspecified population, it got me thinking about something called probability. It sounds fancy, right? Like something you’d find in a dusty textbook. But it’s actually the foundation of so many things we experience every day, even if we don’t realize it.
Think about it. When you flip a coin, you have a 50/50 shot of getting heads or tails. Pretty straightforward. But what happens when you have more options? Like, say, a bag with multiple colors of candy? This is where the magic of randomness starts to weave its spell.
Let’s imagine our giant bag of candies. We don’t know exactly how many of each color are in there. It’s a mystery! Maybe there are tons of red ones, a decent amount of blue, a few lonely yellow ones, and maybe just one elusive orange. Or perhaps they’re distributed perfectly evenly. We just don't know. That's part of the fun – the inherent uncertainty!
And here's the kicker: when we go to select our 100 candies, we're hoping that our selection somehow reflects the "true" proportions of colors in that massive, unseen candy universe. But the universe, my friends, is a fickle mistress. Sometimes it plays fair, and sometimes… well, sometimes it throws you a curveball. Or, in our case, maybe it throws you ten green candies in a row when you were expecting a more even spread.
So, let's break down this whole "random selection of 100 colored candies" scenario. What are we actually looking at here? We're essentially taking a sample from a larger population. The population is the entire, unpicked candy stash. Our sample is the 100 candies we pull out. The goal, often, is to use our sample to try and understand something about the population.
The Big Unknown: What’s Really In The Bag?
This is the central mystery. We don't know the exact number of red, blue, green, yellow, purple, or any other color candies that exist before we start picking. This lack of prior knowledge is crucial. If we knew, for instance, that the manufacturer deliberately put 25 of each color into a bag of 100, then picking 100 would be a guaranteed win for symmetry! But that's not the fun kind of randomness we're talking about here. We’re talking about the delicious, unpredictable chaos of a true random selection.
Imagine a candy factory. They’re churning out bags. Are they perfectly calibrated? Or is there a tiny bit of variation in the machines? Maybe the dye for the red candies runs a little more that day. These tiny imperfections, these little whispers of randomness, are what make the real world so interesting, and sometimes, so frustratingly unfair.
When we talk about a “random selection,” we’re assuming every single candy in that giant bag has an equal chance of being chosen. No candy has a secret VIP pass to the sampling party. This is the ideal scenario, the theoretical playground where probability rules. In real life, perfect randomness can be a bit of a slippery eel, but it’s the best we can aim for.
The Sample: Our Tiny Candy Snapshot
Okay, so we've got our 100 chosen candies. What do we do with them? We count! We meticulously record the number of each color. This is our data. It’s the raw material we’ll use to infer things about the bigger, unseen picture.
Let's say, in our sample of 100, we end up with: 30 red, 25 blue, 15 green, 20 yellow, and 10 purple. This is our particular outcome. It’s the result of this specific random draw. And it’s already giving us some clues, isn’t it? It suggests that perhaps red and blue candies are more common in the original bag than, say, purple.
But here's the crucial part: if we were to do this again, pulling another 100 candies from the same original bag, would we get the exact same numbers? Probably not. This is the essence of randomness. Each selection is independent. It doesn't remember what happened last time. It starts fresh, with its own set of probabilities.
This is where the irony can creep in. You might think, "Okay, 30 red candies means there are definitely a lot of red ones." And you might be right! But you also might be wrong. Your sample, however representative it might seem, is still just a snapshot. It's like looking at a single photograph of a large party – you see who's in that photo, but you don't know who else was there or what they were doing.
The Power (and Perils) of Inference
This is where the real thinking begins. We take our sample data and we try to make an inference about the population. We’re trying to say something like, "Based on the 30 red candies in my sample, I estimate that about 30% of all the candies in the bag are red." This is called making an estimate.
However, there’s always a chance that our sample is a bit… odd. Maybe, just by pure chance, we happened to pick a disproportionately large number of red candies this time. Or maybe, conversely, we were unlucky and missed out on a whole bunch of blue ones that were actually very common. This is what statisticians call sampling error. It’s not a mistake in our counting, but rather the natural variation that occurs when you try to represent a large group with a smaller one.
Think of it like this: if you’re trying to guess the average height of everyone in your city, you wouldn’t go around measuring every single person, right? That would take forever! Instead, you’d measure a smaller group of people (your sample) and then use that information to estimate the average height of the whole city (the population).
The bigger your sample, the more likely it is to be a good representation of the population. If you only measured two people, your estimate might be way off. But if you measured 1,000 people, your estimate would be much more reliable. With our 100 candies, it's a decent sample size for a bag of, say, a few hundred candies. But if the original bag contained a million candies, our 100 might start to feel a little… small.
When Expectations Meet Reality
So, what are we really expecting when we do this random selection? In a truly random process, we’d expect the proportions of colors in our sample to be similar to the proportions in the original population. If, for example, there were actually 50% red candies in the giant bag, we’d expect to get around 50 red candies in our sample of 100. This is the concept of the expected value.
But, and this is a big but, expected doesn't mean guaranteed. The laws of probability are more like strong suggestions than rigid rules, especially with smaller sample sizes. You could flip a coin 10 times and get 7 heads. That's not what you'd expect (which is 5 heads), but it’s certainly possible.
The more times you repeat an experiment, the closer your results tend to get to the expected value. This is known as the Law of Large Numbers. So, if we kept pulling 100 candies, over and over, the average number of red candies we got across all those trials would likely hover very close to the true proportion of red candies in the original bag. It’s like the universe eventually rights itself, but it takes a lot of data points to smooth out the bumps.
The Curious Case of Uncommon Colors
This is where it gets fun for my personal candy conspiracy theories. What about those colors that seem to disappear? If a bag is supposed to have, say, 10% purple candies (meaning 10 out of every 100), in a sample of 100, we might only get 5 purple ones. Or, if we're really unlucky, we might get zero! It's not that the purple candies don't exist; they're just rare enough that they can get lost in the shuffle of a random draw.
Conversely, sometimes you get a "lucky streak." You might pull out 15 green candies when you were only expecting, say, 5. This doesn't mean the candy gods have a special affinity for green. It just means that, for this particular selection, that's how the random dice rolled.
This is why seeing the distribution of colors in our sample of 100 is so fascinating. It’s a tiny window into a potentially much larger and more complex reality of candy production. Are some colors harder to produce consistently? Do some machines just favor certain dyes?
Beyond Candies: Where Else Do We See This?
It’s easy to get lost in the sweet world of confectionery, but this concept of random sampling and inference is everywhere! Think about:
- Polls and Surveys: When a polling company asks 1,000 people about their voting intentions, they're taking a sample of the entire electorate. They’re hoping that this sample is representative enough to predict the election outcome.
- Quality Control: Factories often test a random sample of their products to ensure they meet quality standards. They can’t test every single item, so they rely on samples to catch defects.
- Medical Research: When testing a new drug, scientists typically give it to a sample of patients, not the entire population. They then analyze the results to see if the drug is effective and safe.
- Genetics: Scientists studying genetic traits in a population will often analyze a sample of individuals to understand the genetic makeup of the whole group.
In all these cases, the challenge is the same: how do we use a smaller, manageable group to accurately understand a much larger, potentially unmanageable one? And how do we account for the inherent variability that comes with randomness?
The Bottom Line (or the Bottom of the Bag)
So, the next time you’re faced with a bag of colorful candies and decide to grab a handful, remember that you’re participating in a little bit of statistical magic. Your random selection of 100 candies isn't just a snack; it's a miniature experiment. It’s a chance to glimpse the underlying probabilities that govern the distribution of those sugary spheres.
You might get a perfectly even mix, and you might think, "Wow, they really do put a lot of blue ones in there!" Or you might get a skewed distribution, and you might start to wonder about the candy factory’s secrets. Whatever you get, it’s a testament to the fascinating world of probability and the inherent unpredictability of randomness.
And as for my personal green candy obsession? Well, after all this thinking, I’m still not entirely sure if it’s a statistical anomaly or just my taste buds being weirdly specific. But at least now I have a whole lot more appreciation for the math behind my munchies. Cheers to the randomness, and more importantly, cheers to the delicious data!