Solve The Following Recurrence By Giving The Tightest Bound Possible.

Ever found yourself staring at a problem that seems to unravel into smaller, identical versions of itself? Like a set of Russian nesting dolls, but instead of cute matryoshkas, you're dealing with numbers and computations! That's where the magical world of recurrence relations comes in, and figuring out their tightest bound is like finding the ultimate shortcut to understanding how quickly something grows. It’s not just a math puzzle; it’s the secret sauce behind how we analyze the efficiency of everything from sorting our playlists to powering cutting-edge AI.
Think about it: when you're learning to code, you're constantly thinking about how fast your program will run. Will it chug along slowly, or will it zip through the data like a race car? Recurrence relations are the tools that let us predict this speed. They're particularly popular in computer science because so many algorithms are built on the principle of breaking down a big problem into smaller, more manageable pieces. For example, algorithms like Merge Sort and Quick Sort, which are fundamental to organizing data, are elegantly described and analyzed using recurrence relations.
The real thrill, though, comes with finding the tightest bound. This isn't just about saying something is "big" or "small"; it's about giving the most precise estimate possible. Imagine you're trying to guess how many jellybeans are in a giant jar. You could say there are "a lot." But what if you could say, "There are exactly 1,247 jellybeans"? That's the difference between a loose guess and a tight bound. In the world of algorithms, a tight bound tells us precisely how the running time of a program will scale as the input size increases. This is crucial for making informed decisions about which algorithm to use for a particular task. A slightly better bound can mean the difference between a program that runs in seconds and one that takes hours, or even days!
So, what’s the game plan for cracking these recurrence relations and uncovering their tightest bounds? It's like being a detective, piecing together clues to reveal the underlying pattern. We’re given a formula that defines a problem's size in terms of smaller instances of the same problem, often with some added cost. Our mission is to translate this recursive definition into a direct, non-recursive formula, or at least a very accurate estimate of its growth rate. This is where mathematical magic happens, and it often involves a bit of clever manipulation.
The Case of the Dividing Army
Let's dive into a specific challenge, a classic that often pops up in algorithm analysis. Imagine we have a problem of size 'n', and to solve it, we split it into two roughly equal subproblems of size 'n/2'. This splitting itself takes some effort, let's say a constant amount of work, 'c'. Once we've split it, we recursively solve those two smaller problems. So, if we denote the time it takes to solve a problem of size 'n' as T(n), we can write our recurrence relation:
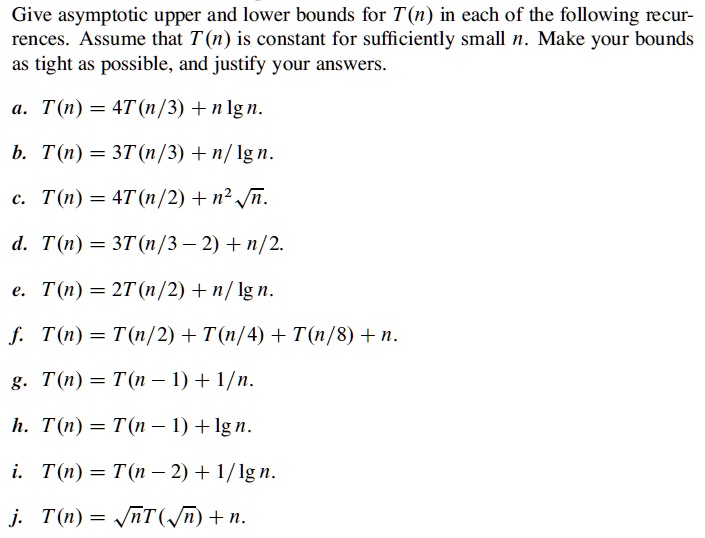
T(n) = 2 * T(n/2) + c
This relation tells us that to solve a problem of size 'n', we do twice the work of solving a problem of size 'n/2', plus a constant amount of work 'c' to divide it. We also need a base case to stop the recursion, which is usually when the problem size is very small, say T(1) = d (another constant representing the work for a minimal problem).
Now, how do we find the tightest bound for this? Several powerful techniques are at our disposal. One of the most elegant is the Master Theorem. This theorem is like a cheat sheet for a common type of recurrence relation, and our example fits its structure perfectly. The Master Theorem helps us compare the cost of dividing the problem with the cost of solving the subproblems. It has different cases, but for our specific relation, T(n) = 2 * T(n/2) + c, we can see that the cost of solving the subproblems (represented by the '2 * T(n/2)') dominates the cost of dividing (the '+ c').

Using the Master Theorem, we can directly determine the tightest bound. In this scenario, where we have 'a' subproblems of size 'n/b' and a cost function 'f(n)', our recurrence is T(n) = a * T(n/b) + f(n). In our case, a = 2, b = 2, and f(n) = c (a constant). The Master Theorem provides a framework to analyze the relationship between f(n) and nlogba. Here, nlog22 = n1 = n. Since our f(n) = c grows slower than n, we fall into a specific case of the Master Theorem.
This particular recurrence relation, T(n) = 2 * T(n/2) + c, is the heartbeat of algorithms like Merge Sort. When you apply the Master Theorem, or even unfold the recurrence a few times, you'll discover that the tightest bound is approximately O(n). This means that the time taken by such an algorithm grows linearly with the size of the input. If you double the input size, the time roughly doubles. This is incredibly efficient and makes these algorithms suitable for handling very large datasets.
The satisfaction of solving a recurrence relation and pinning down its tightest bound is immense. It’s not just about getting the right answer; it's about understanding the fundamental performance characteristics of computational processes. It’s the difference between vaguely knowing a program is "fast" and knowing precisely how it scales, which is essential for building robust, efficient, and scalable software. So, next time you encounter a problem that breaks down into smaller pieces, remember the power of recurrence relations and the elegance of finding their tightest bounds – it's a key to unlocking the secrets of computational efficiency!