Four Fundamental Subspaces Of A Matrix Calculator
Alright, so you've probably seen those fancy calculators in math class, the ones that can do way more than just add 2+2. They have buttons for "matrix," "vector," and all sorts of mysterious symbols that look like they belong in a secret handshake. Well, it turns out these "matrix calculators" aren't just showing off. They're actually incredibly useful tools for understanding some really deep stuff about how information is organized and transformed. And believe it or not, you've probably encountered these concepts in your everyday life, even if you didn't have a name for them. Think of it like this: sometimes you know how to make a killer sandwich without knowing the exact chemical reactions happening in your mouth. Same vibe here, but with numbers and lines.
We're going to dive into what the smarty-pants mathematicians call the "four fundamental subspaces" of a matrix. Now, don't let the "subspace" part freak you out. It's not like we're talking about parallel universes or anything. Think of it more like different "neighborhoods" or "departments" within the big city of a matrix. Each neighborhood has its own rules, its own vibe, and its own special job to do. And understanding these neighborhoods helps us understand what a matrix is really doing when it takes your numbers and shuffles them around.
Imagine you're packing for a trip. You've got a suitcase, right? That suitcase is your matrix. It holds all your stuff (your numbers, your data, your potential to wear mismatched socks). Now, the four fundamental subspaces are like the different compartments and pockets within that suitcase, and also the ways you can arrange your clothes. You've got your main compartment for big things, a little zippered pocket for your underwear (super important!), maybe a side pocket for your toiletries. Each has a purpose. And how you pack it all – neat folds, rolled-up shirts – that's kind of like how a matrix transforms things.
So, let's get our metaphorical hands dirty and explore these four key areas. It’s going to be a bit like a guided tour of a really efficient filing cabinet, but way more interesting, I promise! And if at any point you feel like you’re back in a lecture, just picture me holding up a slightly crumpled sock as an example. That usually helps.
The First Neighborhood: The Column Space (aka "The Reachable Zone")
First up, we've got the column space. Think of this as the "What can this matrix do?" neighborhood. Imagine your matrix is a superhero team. The column space is all the powers that team collectively possesses. It's the set of all possible outcomes you can get if you apply the matrix to any vector. A vector, by the way, is just a list of numbers, like [1, 2, 3]. So, if you have a matrix and you multiply it by different vectors, all the resulting vectors that you can produce? That's the column space.
Think about it like this: You’re at a buffet. The column space is all the food you can possibly get from that buffet. You can grab some salad, some pasta, maybe a dessert. You can’t, however, magically conjure up a plate of sushi if the buffet doesn't offer it, right? The matrix, in this analogy, is the buffet table, and the vectors are your choices of what to put on your plate. The column space is the grand total of all the delicious (or questionable) combinations you can assemble.
Or consider a ridiculously simple example. Let’s say your matrix is just a single number, like 5. And you can multiply this by any number (vector). So, you can get 51 = 5, 52 = 10, 5(-3) = -15. The column space here is essentially *all the multiples of 5. You can reach any number that's divisible by 5. You can’t get 7, though. Seven is outside your "reach."
In more technical terms, the column space is formed by taking linear combinations of the columns of the matrix. That’s just a fancy way of saying you multiply each column by some number and then add them all up. If you can create a target vector by doing this, then that target vector is in the column space. It’s the matrix's domain of influence, if you will. It’s the set of all destinations it can send you to.

When we're talking about data, the column space tells us about the span of our features. If you're looking at, say, house prices, and your columns represent things like "square footage" and "number of bedrooms," the column space is all the possible price points you can logically achieve with those features. It gives you a sense of the range of possibilities.
The Second Neighborhood: The Null Space (aka "The Zone of Nothingness")
Now, let's meet the null space. This one is kind of the opposite of the column space. If the column space is about what the matrix can do, the null space is about what vectors get squashed into oblivion by the matrix. Think of it as the set of all vectors that, when you multiply them by the matrix, result in the zero vector – that's a vector where all the numbers are zero, like [0, 0, 0].
Imagine you have a magic shrinking machine (the matrix). The null space is the collection of all things (vectors) that, when you put them into the machine, come out as nothing. Just gone. Poof! Like putting a single grain of sand into a super-powerful industrial shredder. It’s not that the shredder can’t shred, it’s just that this particular grain of sand has no impact.
Let’s use that buffet analogy again. If the column space is all the food you can get, the null space is like the ingredients you can ignore entirely and still end up with the same meal. It's a bit weird to think about in a buffet, but imagine you have a recipe that uses 10 ingredients. If you have a secret ingredient that doesn't affect the final taste at all, then that secret ingredient is in the "null space" of the recipe. Adding it or not adding it makes no difference to the outcome.
This is super important when we're talking about solving systems of equations. If you have a system like Ax = b (matrix A times vector x equals vector b), and you find one solution x₀, then any other solution x will be of the form x₀ + x_n, where x_n is in the null space of A. This means if there's a non-trivial null space (meaning there are vectors other than the zero vector in it), there are infinitely many solutions to Ax = b. It’s like having multiple paths that lead to the same destination.
Think about a leaky faucet. The water dripping out is the result of the matrix operation. If there are certain settings on the faucet (vectors in the null space) that, no matter how long you leave them, produce no dripping at all, those settings are in the null space. They have zero effect. It’s the “do nothing” button.
The Third Neighborhood: The Row Space (aka "The Input's Essence")
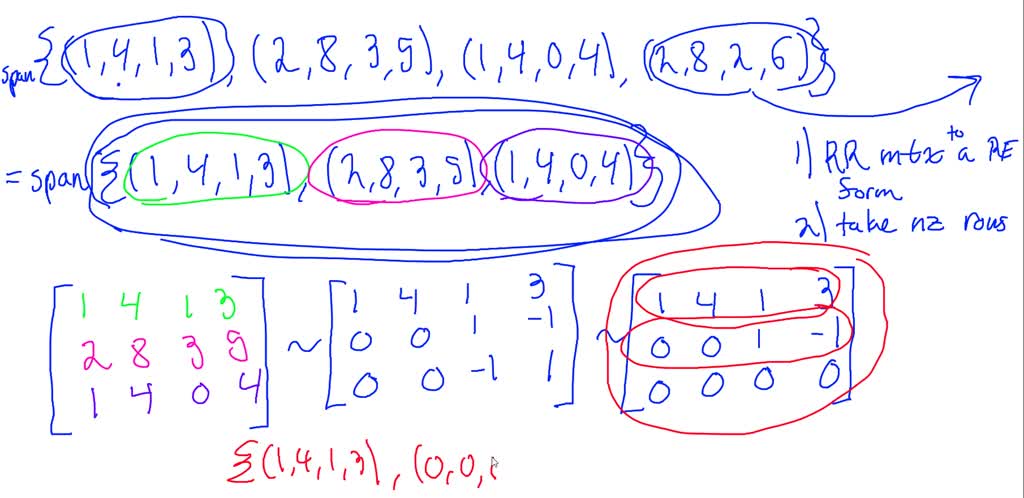
Now we move on to the row space. This is closely related to the column space, but it’s about the rows of the matrix instead of the columns. Think of the rows of your matrix as different "criteria" or "tests" that your input vectors have to pass. The row space is the set of all possible outcomes you can get by taking linear combinations of these rows.
Imagine you're grading essays. Each row of the matrix could represent a different grading rubric: one for grammar, one for content, one for originality. The row space is all the possible combinations of scores you can give an essay based on these rubrics. You can’t give an essay a score that doesn't align with any combination of your grading criteria. It's the "essence" of your inputs.
Let's go back to the suitcase. The rows of the matrix are like the types of items you could pack. You have space for clothes, for toiletries, for books. The row space is the set of all valid combinations of item categories you can fill your suitcase with. You can pack a lot of clothes and a few toiletries, or a lot of books and no toiletries, but the proportions are constrained by what the suitcase "allows."
A really neat thing about the row space is that it tells you about the linear independence of the rows. If the row space has a certain "dimension" (which we’ll get to later!), it means you have that many rows that are fundamentally different from each other. If a row is just a combination of other rows, it doesn't add anything new to the row space. It's redundant, like having two identical instruction manuals for assembling IKEA furniture.
When we're dealing with data, the row space is related to the features themselves. It tells us about the relationships and dependencies between the different characteristics of our data. If one feature can be perfectly predicted from others, it's not adding a whole lot to the row space. It's like having a "color" feature and a "shade" feature that are always directly related.
The Fourth Neighborhood: The Left Null Space (aka "The Annihilators")
Finally, we arrive at the left null space. This one is a bit like the null space, but it works from the "left" side of the matrix. Remember how the null space tells us what vectors get zeroed out when you multiply them on the right (Ax = 0)? The left null space tells us what vectors, when you multiply them on the left, get zeroed out by the matrix (yᵀA = 0).
Think of your matrix as a bouncer at a club. The null space is the list of people who can walk right past the bouncer without any effect. The left null space is the list of people who, if they try to approach the bouncer from the "VIP entrance" (the left side), will get immediately turned away with nothing. They're the "annihilators" from the left.
Let's bring back the essay grading analogy. If the row space is about the grading criteria, the left null space is like a set of "penalty scores" that, when applied to the grading matrix, result in a perfect score of zero for any essay. It’s a way to find combinations of penalty points that essentially cancel out any grading outcome.
Imagine you have a set of equations that are all a bit "redundant." For example, you might have: Equation 1: x + y = 5 Equation 2: 2x + 2y = 10 Equation 3: x + y + z = 7 Notice that Equation 2 is just 2 times Equation 1. If you were to create a "combination" of these equations that cancels everything out, that combination would live in the left null space. For instance, if you took -2 times Equation 1 and added it to Equation 2, you’d get 0 = 0. That "-2" and "1" (for Equation 2) would be part of a vector in the left null space.
The left null space is also crucial for understanding the consistency of systems of linear equations. If you have a system Ax = b, it has a solution if and only if the vector b is "orthogonal" to the left null space of A. In simpler terms, b can't be "canceled out" by any of the annihilators from the left. If it can be canceled out, then there's no solution. It's like trying to win a game where the rules are rigged against you in a very specific way.

Putting It All Together: The Big Picture
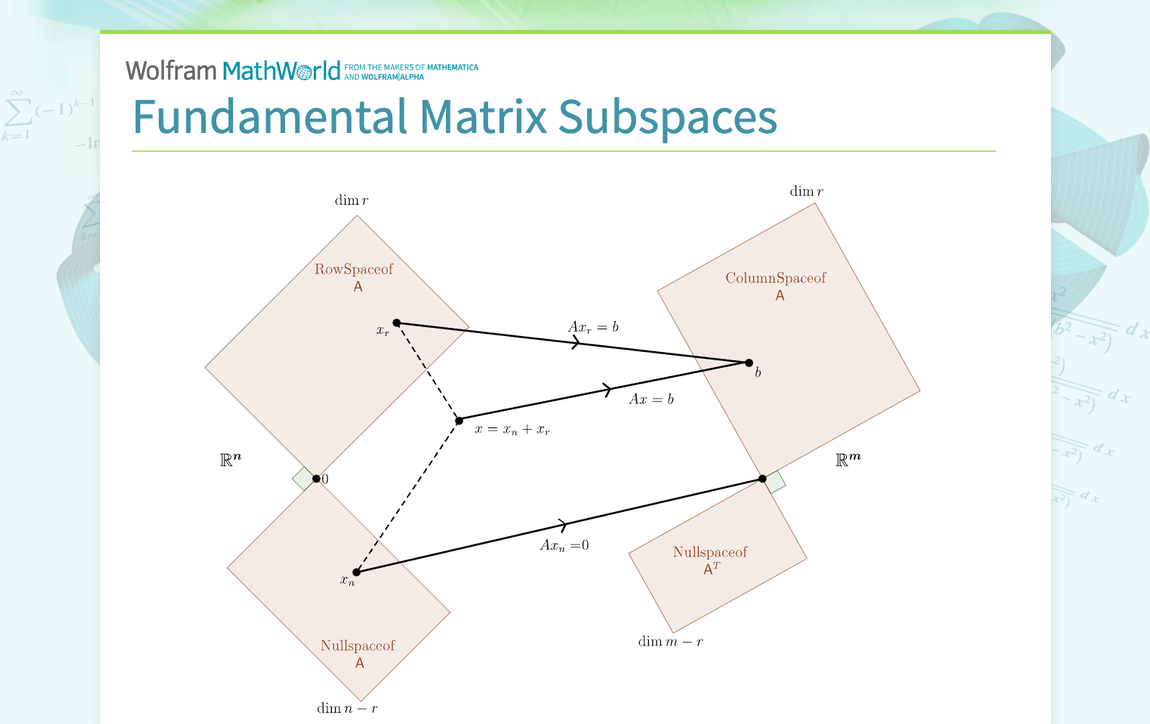
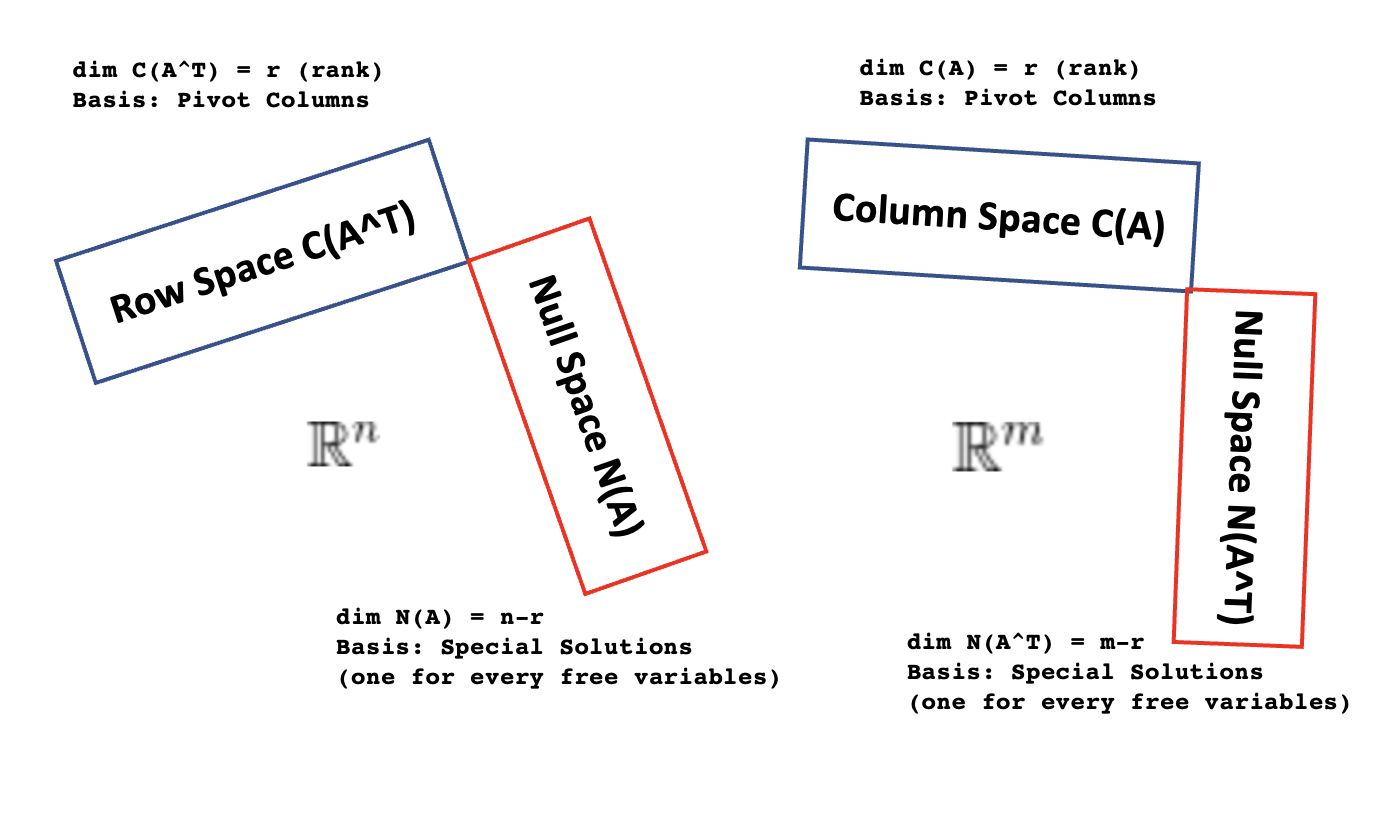
So, we've got these four neighborhoods: the column space (what the matrix can do), the null space (what gets zeroed out), the row space (the essence of the inputs), and the left null space (what annihilates from the left). These four subspaces are not just random collections of numbers. They are intrinsically linked, and their "sizes" (called dimensions) are particularly important.
The dimension of the column space is called the rank of the matrix. And here's a mind-blowing fact: the rank of the matrix is equal to the dimension of the row space! This means the number of independent "powers" the matrix has is the same as the number of independent "criteria" it uses. It’s like saying the number of unique skills your superhero team possesses is equal to the number of unique abilities they were trained with.
Also, there's a beautiful relationship involving the null space. The dimension of the null space (often called the nullity) plus the rank of the matrix always equals the number of columns in the matrix. This is called the Rank-Nullity Theorem. It means that the "reach" of the matrix plus the "stuff that gets lost" always adds up to the total "input space."
Similarly, the dimension of the left null space plus the rank of the matrix equals the number of rows in the matrix. This tells us that the "annihilators from the left" and the "reach" of the matrix add up to the total "output space" (or the space where the results live).
Why is this important in the real world? Think about compression algorithms, image processing, or even recommending movies on Netflix. These all rely on understanding how data can be transformed and what the fundamental components of that transformation are. Knowing these four subspaces helps us understand:
- How much information is being preserved? (Related to rank)
- Are there redundancies in the data? (Related to nullity and dimensions of row/column spaces)
- Can a given problem even have a solution? (Related to left null space and column space)
- What are the most important "directions" or "features" in the data? (Related to eigenvectors and singular value decomposition, which are built upon these subspaces)
So, the next time you use a matrix calculator and see it spitting out numbers for column space, null space, and all that jazz, don't just think of it as a bunch of math jargon. Think of it as exploring the different "neighborhoods" of information, understanding what's reachable, what gets lost, and what makes the whole system tick. It’s like having a map to a complex city, and these four subspaces are your essential guide to navigating its most important districts. And who knows, maybe understanding them will help you pack your next suitcase more efficiently! Or at least understand why that one weird sock always seems to disappear into its own personal null space in the laundry. Happy calculating!